
计算机组成原理小记
本是为了考试做的复习笔记,但是说到底也是些有意思的知识,留个笔记用以温故而知新
一.基础知识
1.体系结构与组织
- 体系结构->对程序员可见的部分
如指令集(move),用于数据表示的位数(“uint_8”中的8),I/O机制(gpio_init/gpio_set),寻址技术(jump)
- 组织->计算机的各类特征具体的实现
如信号控制(uart,iic),接口(usb/9mm),存储技术(cache/eeprom)
功能是结构各组件的操作(老师教书,学生上课)
结构是各组件之间的关联(老师教学生)
2.计算机内部结构
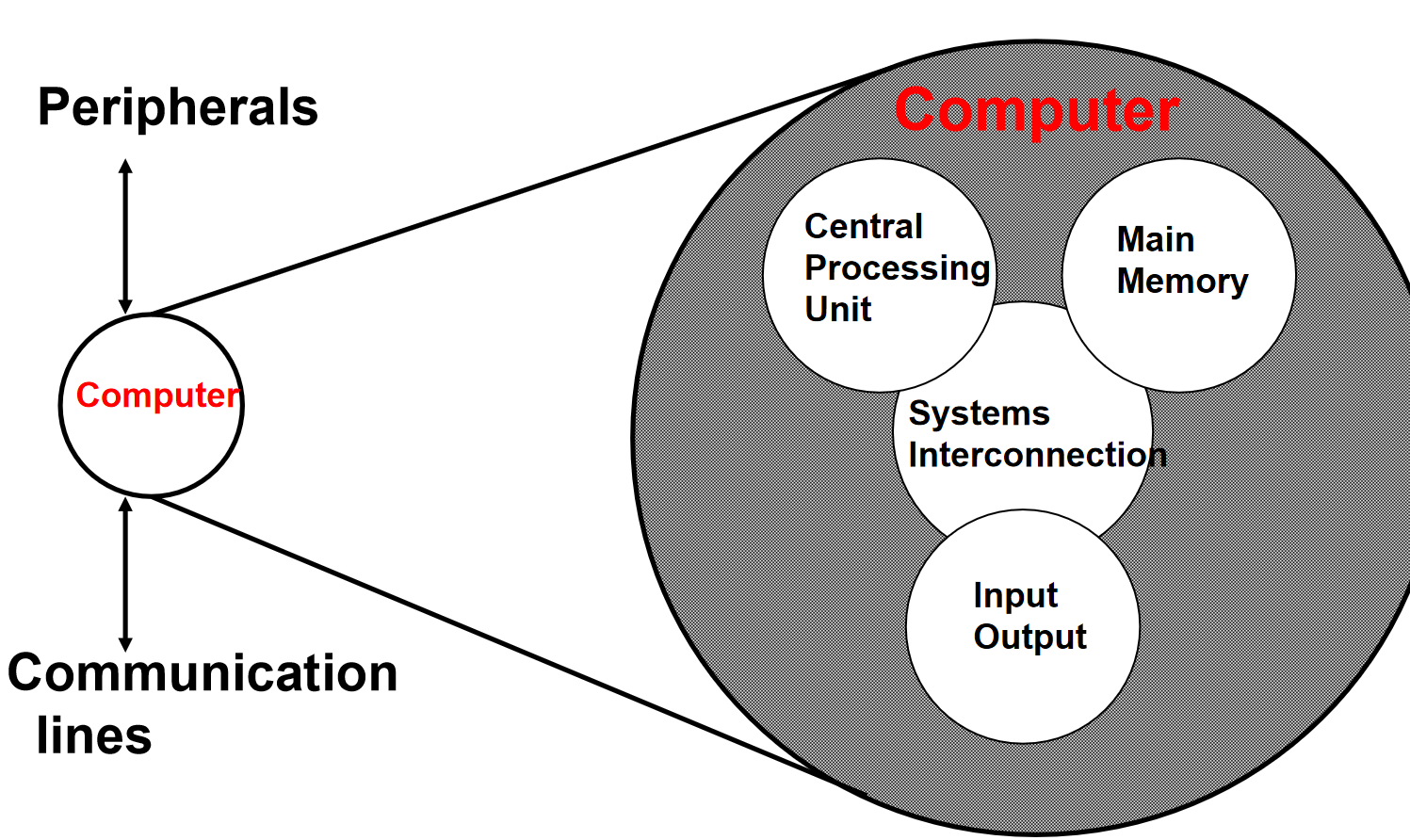
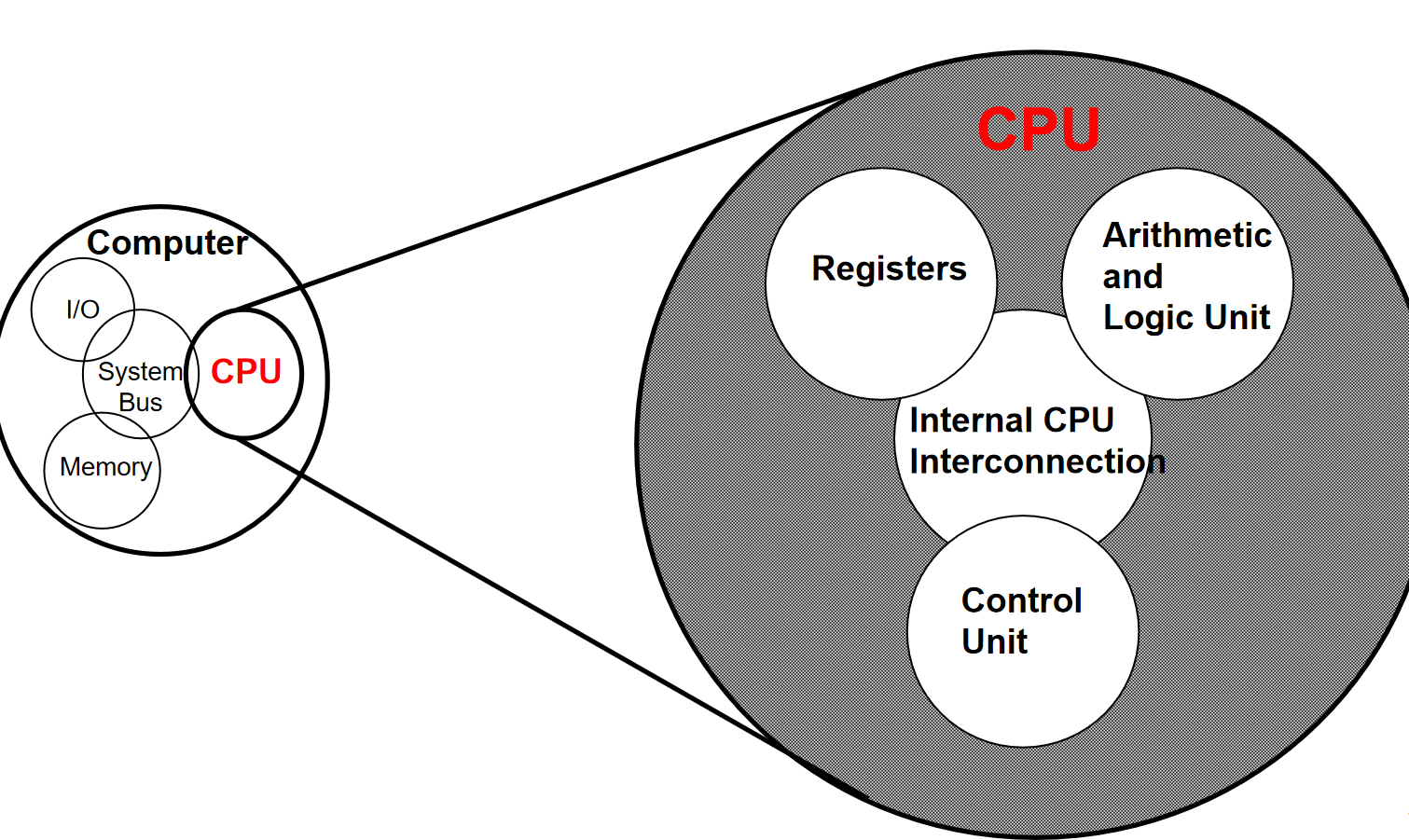
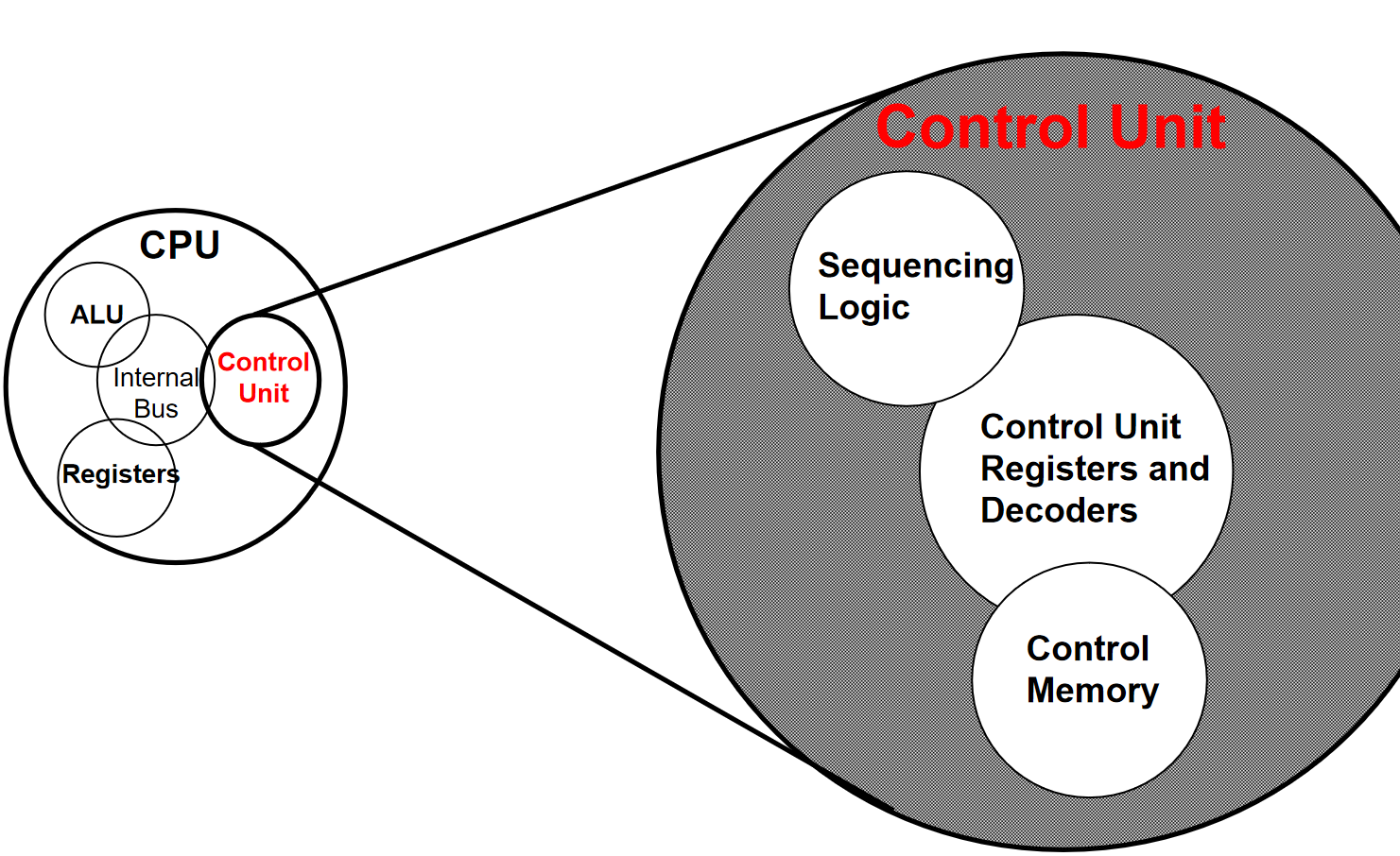
3.冯诺依曼架构的关键
数据和指令存储在单个读写存储器中
对二进制数据进行操作的 ALU
内存可寻址
从一个到另一个的执行指令
4.总线
系统总线连接 处理器主存与IO
数据线 ,总线宽度是衡量性能的关键指标
地址线,总线宽度决定了系统的最大内存容量(多少个位置)2的n次方
总线的设计要素
类型,仲裁方式,时序,总线宽度
二.存储系统
1.特征总览
位置
内部存储:Register,Cache,Main Memory
外部存储:磁盘,光盘,磁带 [一些外围存储设备,有IO控制器访问]
容量
自然单元:字 [字长指一个字有几位]
可寻址单元:有唯一地址的最小位置
传输单元
一个周期内读写几位
内部:一般由数据总线决定(一个字)
外部:磁盘上的群集,通常是比一个字大的块
访问方法
直接访问:CPU 可以直接访问存储器中的任何一个地址,而无需访问其他地址。每个地址都有一个唯一的物理地址,CPU 可以直接使用该地址访问数据。如磁盘
顺序访问:CPU 必须按照数据存储的线性顺序访问数据,从第一个地址开始,依次访问下一个地址,直到找到目标数据。如磁带
相联访问:CPU 不是通过地址访问数据,而是通过数据的内容进行访问。存储器中的每个存储单元都包含一个比较器,CPU 将要查找的数据与所有存储单元中的数据进行比较,如果匹配则返回该数据。如Cache
随机访问:CPU 可以以任何顺序访问存储器中的任何地址,访问时间与地址无关。这是最灵活的访问方式。[区别于直接访问,随机访问不要求每个地址都有唯一的物理地址] 如RAM
性能
- 访问时间:是指从发出读取或写入数据的请求[指地址出现]到数据实际被读写所需的时间。简单来说,就是找到并获取数据所需的时间。
- 存储周期:访问时间+恢复时间 [在下次访问之前,可能需要一些时间才能让内存恢复]
- 传输率:数据进出存储单元的速率
物理类型
- 半导体存储器:RAM
- 磁表面存储器:磁盘,磁带
- 光学存储器:DVD/CD
物理特性
- 衰减: 存储介质上的数据信号随着时间推移而减弱或消失的现象
- 易失性:存储介质需要持续供电才能保持数据的特性。断电后,数据会丢失,如RAM。
- 可擦除:存储介质上的数据可以被擦除并重新写入新数据的特性
组织
存储单元在系统中的排列方式。
2.随机存储
DRAM
- 数据以电荷的形式存储在电容器中 (电容器). 由于电容器本身的特性,存储的电荷会随着时间推移而泄漏,导致数据丢失。
- 为了弥补电荷泄漏,即使在通电状态下也需要刷新 (刷新) ,并且需要专门用于刷新的电路,由于需要刷新,访问速度也较慢
- 结构更简单,每个比特的尺寸更小,可以实现更高的存储密度,所以成本也更低。
- 常用于主存
SRAM
- 数据以开关的开/关状态存储,SRAM 使用晶体管构成的锁存器(Latch)来存储数据,因此没有电荷泄露。
- 没有电荷泄漏,通电时不需要刷新,更不需要刷新电路,因此保持着更快的访问速度
- 结构更复杂,每个比特的尺寸更大,所以成本也更高。
- 常用作高速缓存。
ROM
- 非易失性,常用于存储微程序、库子程序、系统BIOS、功能表
- ROM 类型:Mask ROM [在制造过程中写入数据,永久性存储],PROM [可用专用设备编程一次],EPROM[可擦除可编程,使用紫外线擦除],EEPROM[可电擦除可编程,写入速度比读取速度慢很多],Flash [一种 EEPROM,可以以块为单位进行电擦除]
3.组织方式
- 如何用8个256K x 1位的芯片组合成一个 256K x 8位的芯片。
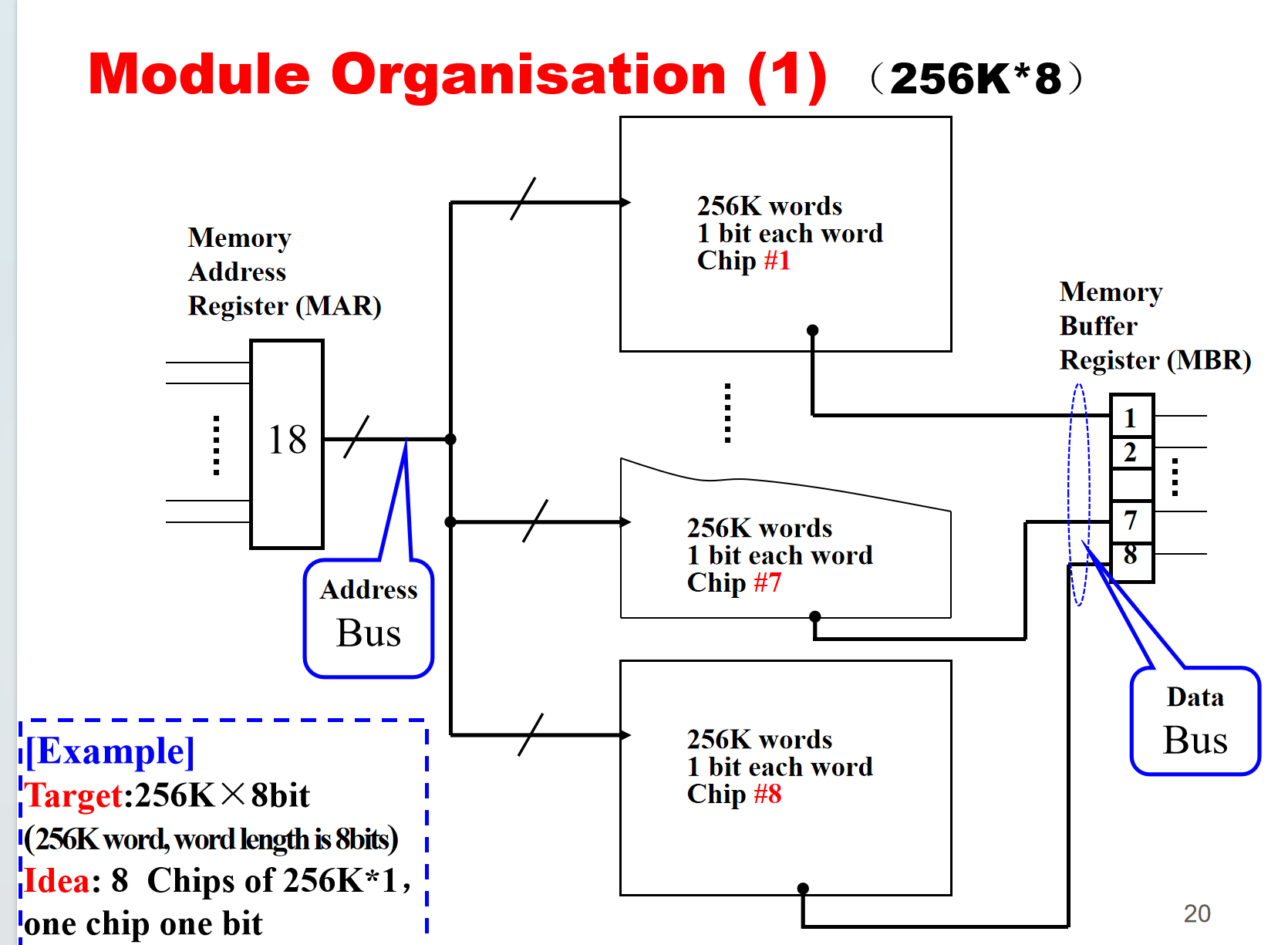
地址线相连即可,剩下每个芯片连接到数据总线上对应的一位
- 如何用多个256K x 1位的芯片组合成一个1M x 8位的芯片。
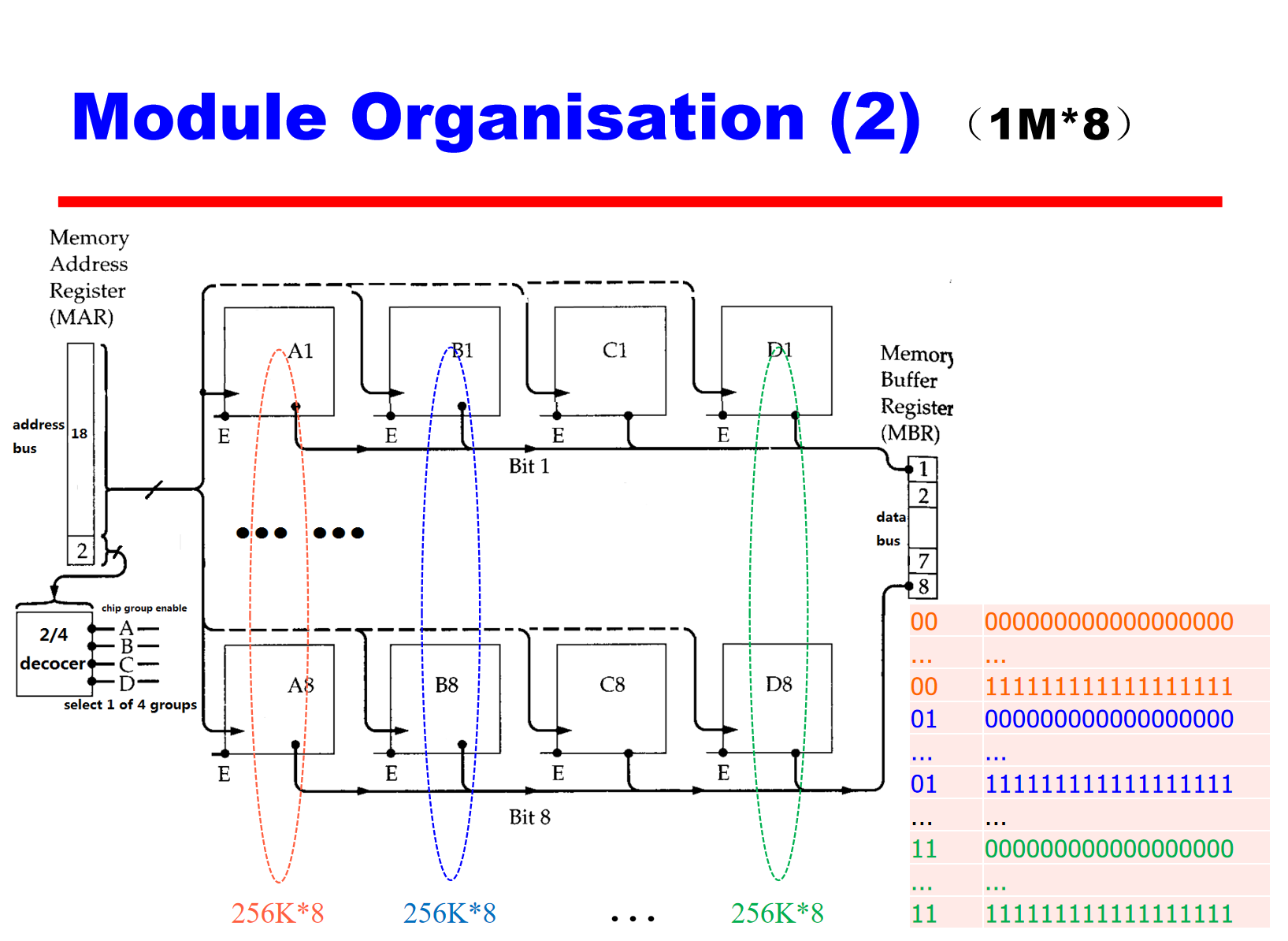
所有模块的地址线连接到同一个地址总线 (Address Bus)。
所有模块的数据线连接到同一个数据总线 (Data Bus)。
地址总线的低 18 位连接到所有模块。
地址总线的最高 2 位连接到译码器。
译码器的输出连接到每个模块的片选信号 (Chip Enable)。
DRAM的组织方式

假设我们有一个容量为 16Mbit 的 DRAM 芯片。
我们可以将这 16Mbit 组织成一个 2048 行 x 2048 列 x 4bit 的矩阵。这意味着每行有 2048 个存储单元,每个单元存储 4bit 数据。
如果直接使用独立的引脚来寻址每一行和每一列,我们需要 22 根地址引脚 (2^22 = 4M > 2048 x 2048)。
为了减少地址引脚的数量,DRAM 采 用了地址复用的技术。芯片会先传输 11 位行地址,然后再传输 11 位列地址,总共只需要 11 根地址引脚 (2^11 = 2048)。
每增加一个地址引脚,可寻址的范围就会翻倍,因此容量也会增加 4 倍。
4.缓存设计
缓存操作流程
CPU请求内存地址的内容——>
检查缓存中是否有该数据——>
如果存在,则从缓存中获取数据——>
如果不存在,则从主内存中读取所需的数据块 (固定字数) 到缓存中,然后将目标数据字从缓存传送给CPU [注意:缓存包含标签,用于标识每个缓存行中存储的是哪个主内存块]
映射方式
直接映射
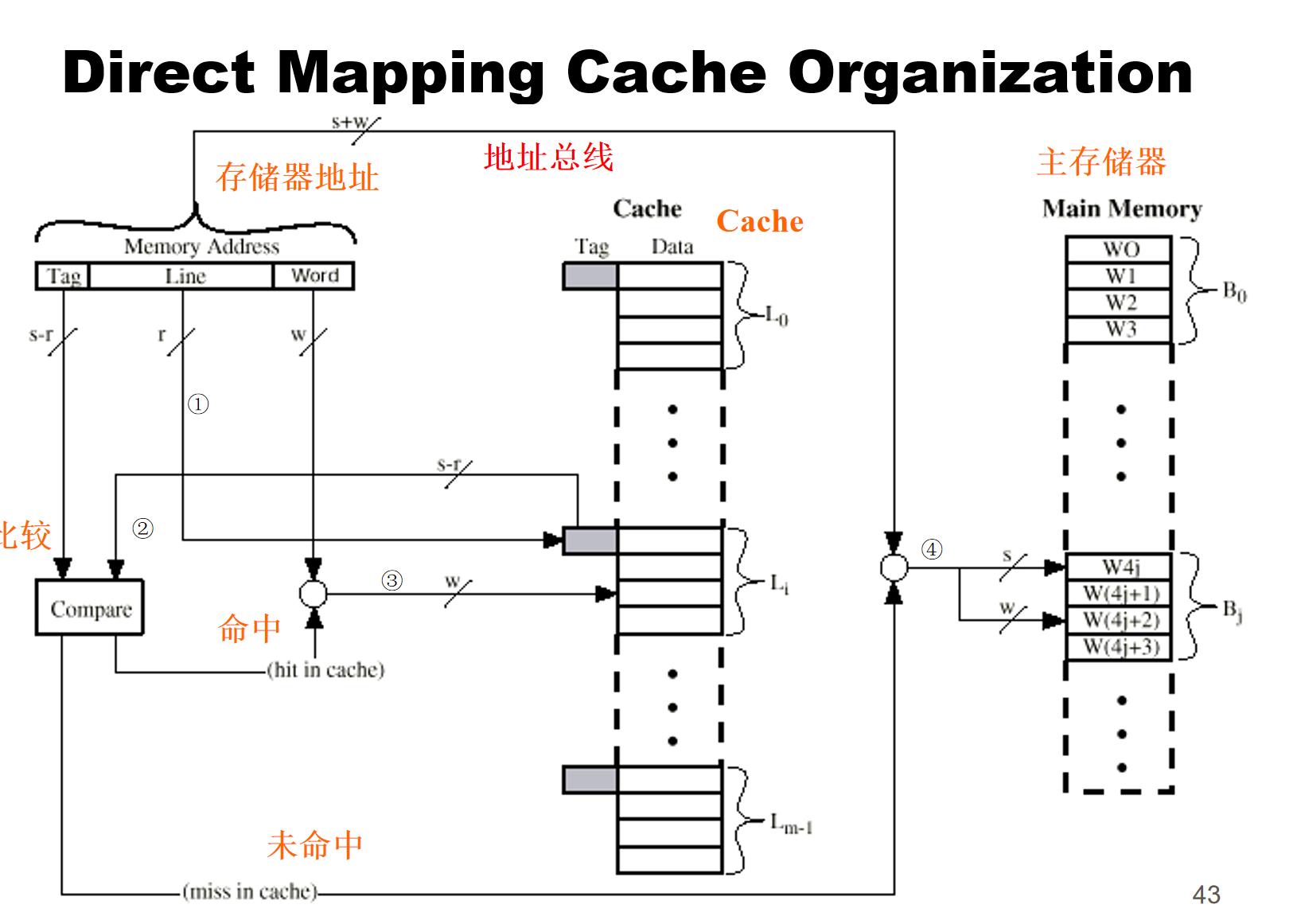
主存中一个内存块占据Cache中的一行
首先一个用于标志块中指定的字的标志w是被需要的
我们先用r位2进制数给行一个编号,即有2^r行
再用s位2进制数给主存中块进行编号,即有2^s个块
2^s个块分配给2^r个行,共要分2^(s-r)个分区
所以s-r位2进制数的编号可以直接索引到对应的分区
假如总共有8辆车停放在2个停车位上,则要分2^(3-1)四区[000,001],[010,011],[100,101],[110,111]
说明2位2进制编号可以索引到对应的分区,事实上也正式如此[00],[01],[10],[11]
缺点:如果程序需要访问映射到x行且tag为y的数据,但现在x行上的tag是z,说明没有命中。即程序访问映射到同一行的不同tag数据命中率会非常低
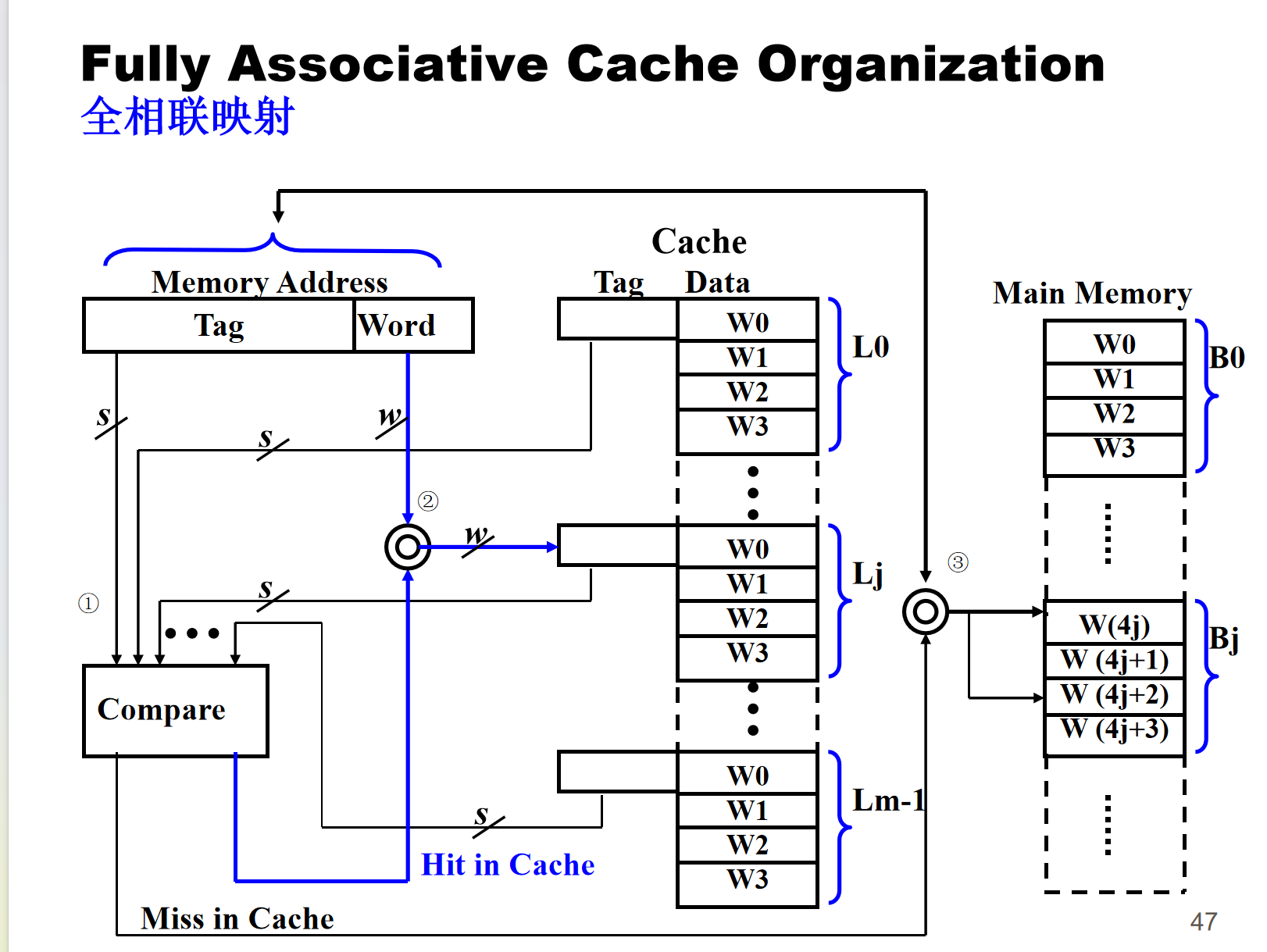
- 全相联映射
主内存块可以加载到缓存的任何一行,内存地址被解释为标签和字 [区别于直接映射的标签,行号和字]
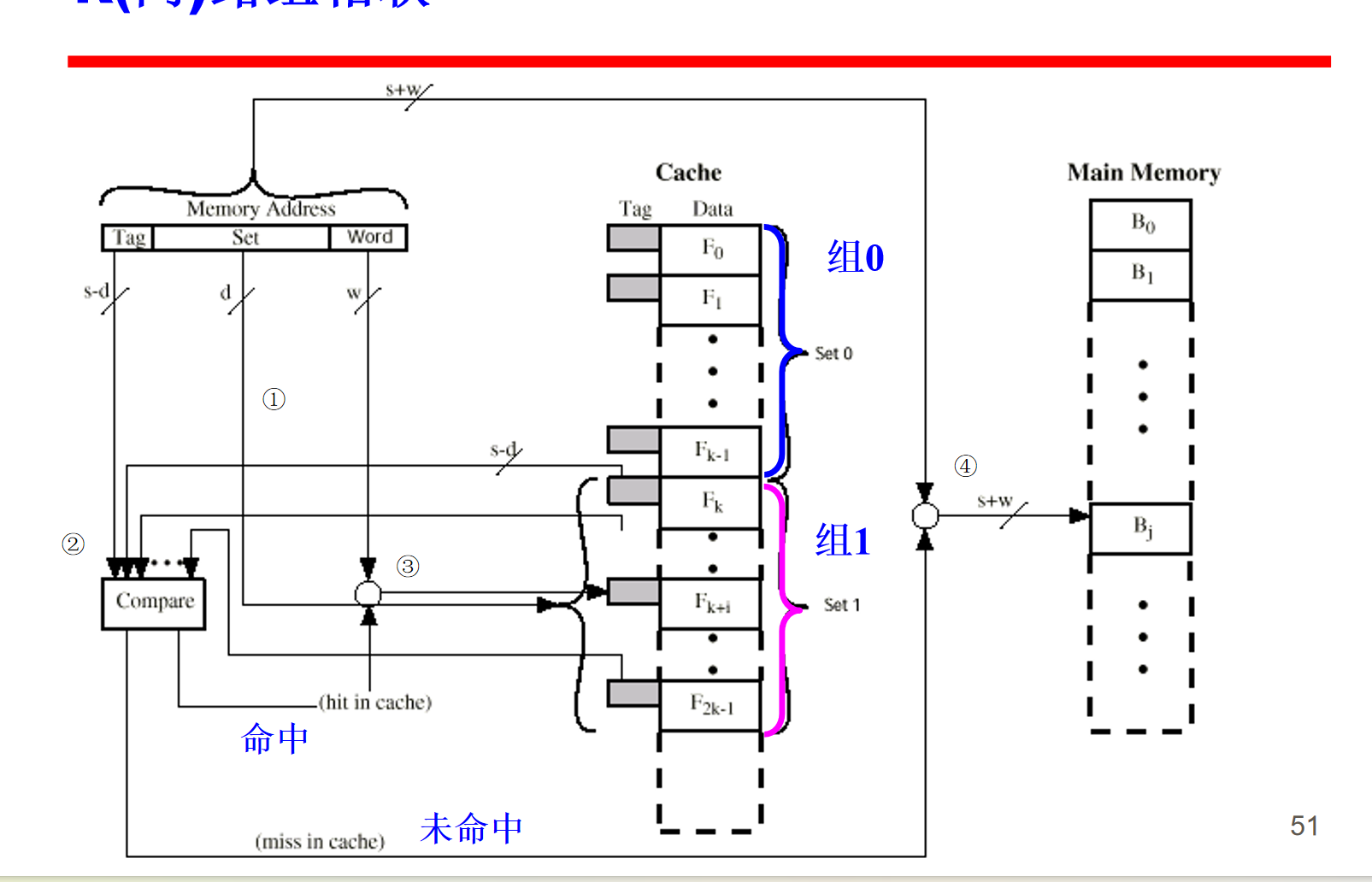
- 组相联映射
缓存被划分为若干组,每个组包含若干行 [直接映射的特征],一个给定的块可以映射到给定组中的任何一行[全相联映射的特征]
其实就是把2^r个行分为d组,然后不再以s-r为标志,而是以s-d为标志
此时不用担心直接映射同行不同tag的问题,只会出现同组不同tag的问题,但是不同tag的数据可以关联映射到这组的不同行中,解决了直接映射的问题
替换算法
- 直接映射: 别无选择,直接替换某行的数据
- 相联映射: 硬件实现算法(速度快),最近最少使用LRU(最近最少使用的块被替换),先进先出 (替换在缓存中最久的块),最不常用LFU(替换命中次数最少的块),随机选择一个块进行替换
写策略
- 写透策略(完全写/写直达)
- 所有写入操作都会同时写入主内存和缓存,每次写入数据时,都会更新主内存和缓存中的对应位置,确保数据一致性。
- 多个 CPU 可以监控主内存流量,以保持本地(CPU)缓存的最新状态。
- 由于每次写入操作都需要更新主内存,因此写透策略会导致大量的内存流量,尤其是在频繁写入数据的情况下。
- 由于需要等待主内存写入完成,因此写透策略会降低写入操作的速度。
- 写回策略
- 更新操作最初只在缓存中进行,而不会立即更新主内存。
- 当发生更新时,缓存槽的更新位会被设置, 缓存使用更新位来跟踪哪些数据块已经被修改。当缓存已满,需要加载新的数据块时,会检查要被替换的数据块的更新位。如果更新位被设置,则表示该数据块已经被修改,需要先将其写入主内存。
- 由于写回策略不会立即更新主内存,因此其他 CPU 的缓存中可能包含过时的数据。
- I/O 操作必须通过缓存访问主内存
5.其他知识
- 错误校验
硬错误是永久性的,会导致数据丢失。
软错误是随机发生的,不会造成永久性损坏,可以使用汉明码进行检测和纠正。
纠错码流程:
原始数据 (M 位) 和由编码函数 (f) 生成的校验位 (K 位) 一起输入系统,并存储在内存中。
当读取数据时,读取出的数据 (M 位) 再次经过编码函数 (f) 生成新的校验位 (K 位)。
新生成的校验位 (K 位) 与从内存读取的校验位 (K 位) 进行比较:
如果两组校验位相同,则表示没有错误。
如果两组校验位不同,但错误在可纠正范围内,则 “Corrector” 模块会纠正错误。
如果两组校验位不同,且错误超出了可纠正范围,则会发出错误信号,表示数据已损坏。
- 局部性原理
两个方面:
时间局部性 (Temporal Locality): 如果一个内存位置被访问,那么它在不久的将来很可能被再次访问。例如,循环体内的变量、函数调用时的返回地址等。
空间局部性 (Spatial Locality): 如果一个内存位置被访问,那么它附近的内存位置也很可能被访问。例如,顺序执行的代码、数组元素的访问等。
意义:
提高缓存命中率: 由于程序访问内存的局部性特征,可以将经常访问的数据存储在速度更快的缓存中,从而减少访问内存的平均时间,提高程序的执行效率。
优化内存管理: 操作系统可以根据局部性原理,将经常访问的数据页调入内存,并将不常访问的数据页换出到磁盘,从而提高内存的利用率。
三.输入与输出
1.I/O模块
为什么需要I/O模块?
不同种类的外围设备具有不同的数据传输量,不同的速度与不同的格式;并且都比CPU与RAM要慢。
典型I/O模块如何工作(输入为例)?
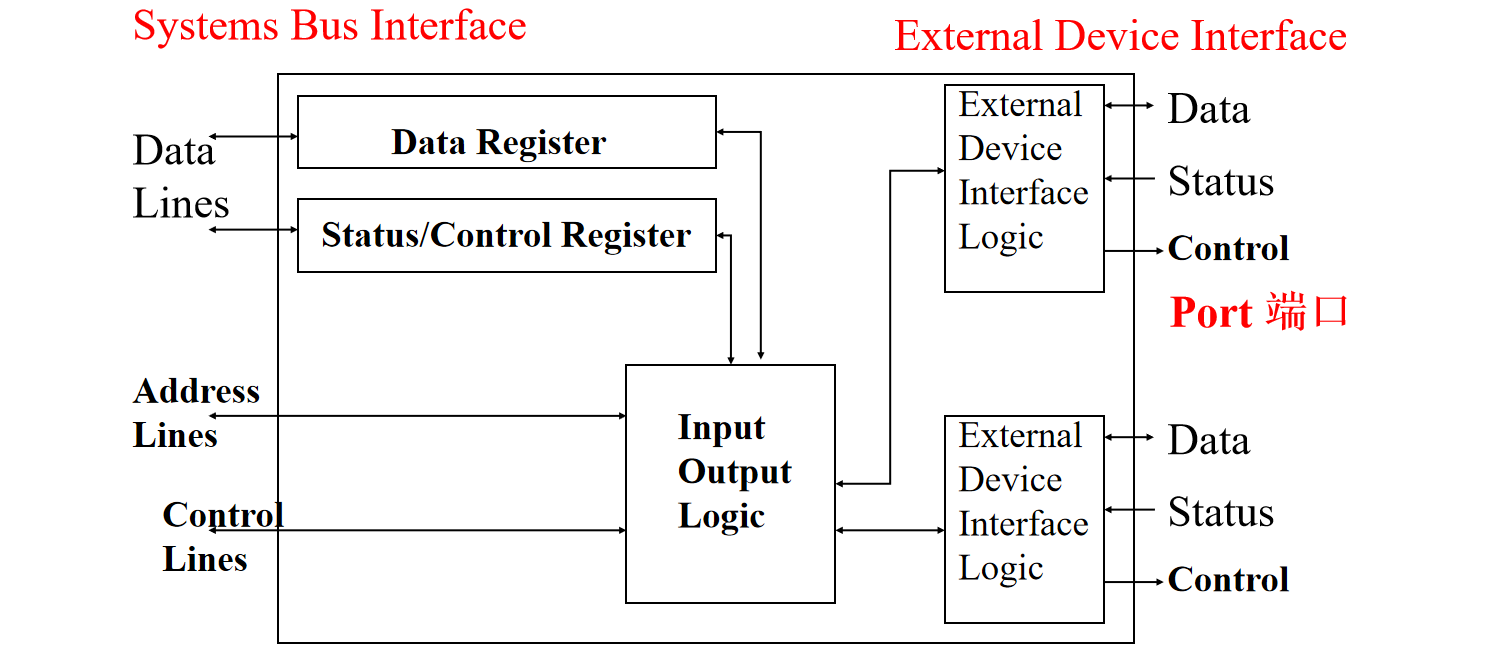
- CPU 会先向目标 I/O 模块发送信号,查询其是否准备好进行数据传输。
- I/O 模块收到查询信号后,会返回自身状态信息,例如是否空闲、是否准备好接收指令等。
- 如果准备好,CPU 请求数据传输
- I/O 模块收到请求后,会从连接的外部设备读取数据,将读取到的数据通过系统总线传输给 CPU。
输出操作的数据流向与输入相反
2.程序I/O
CPU视角
- 感知状态: CPU 需要不断查询 I/O 模块的状态,以确定其是否准备好进行数据传输。
- 读/写命令: CPU 向 I/O 模块发送读/写命令,指示其执行相应操作。
- 传输数据: CPU 在 I/O 模块和内存之间进行数据传输。
程序化I/O特点
I/O 模块不会主动通知 CPU 操作的完成情况,CPU 需要主动查询。
I/O 操作不会中断 CPU 的正常执行流程,CPU 需要等待 I/O 操作完成。
I/O命令
每个 I/O 命令都包含两部分信息:地址,命令
- 控制命令 : 用于控制 I/O 模块的行为,例如启动磁盘旋转 (spin up disk)。
- 测试命令: 用于检查 I/O 模块的状态,例如检查电源是否打开 (power on) 或是否有错误 (Error)。
- 读/写命令: 用于从 I/O 模块读取数据或向其写入数据。数据传输通常通过缓冲区 (buffer) 进行,即 CPU 将数据写入 I/O 模块的缓冲区,或从缓冲区读取数据。
I/O寻址
为了与 I/O 设备进行交互,CPU 使用类似于内存访问的方式来寻址 I/O 设备。每个 I/O 设备都有一个唯一的标识符 (地址),CPU 通过在命令中包含该标识符来选择要访问的设备。
编址方式:
- 内存映射 I/O (存储器映像 I/O / 统一编址)
- I/O 设备的寄存器被映射到 CPU 的内存地址空间中,设备和内存共享相同的地址空间
- CPU 使用相同的指令集来读取和写入内存和 I/O 设备,无需为 I/O 模块使用特殊的命令,简化了编程模型。
- 独立 I/O (单独编址 I/O)
- I/O 设备拥有独立于内存的地址空间。
- 需要 I/O 或内存选择线,来区分 CPU 正在访问的是内存地址还是 I/O 地址。
- CPU 需要使用专门的 I/O 指令来访问 I/O 设备,且I/O 指令集有限。
3.中断I/O
CPU视角
- CPU 向 I/O 模块发出读取数据的指令。
- CPU 不等待数据返回,而是继续执行其他指令和任务。
- 在每个指令周期结束时CPU 会检查是否有中断请求信号。
- 如果发生中断:保存上下文,CPU 跳转到中断处理程序,从 I/O 模块获取数据。
识别是哪个模块发起的的中断?
- 可以使用多条中断线
- 可以通过总线使用软件论询的方式, CPU 执行的程序来识别中断源
- 通过”雏菊链”的方式,即一种硬件轮询机制
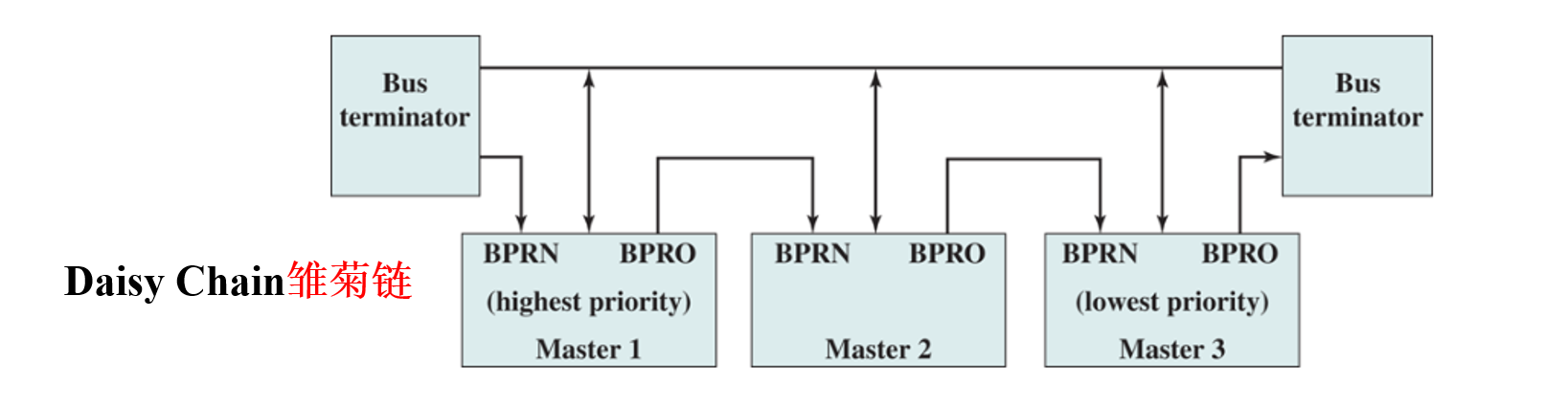
- 多个设备(Master 1,Master 2,Master 3)通过菊花链连接到总线上,每个设备都有一个 BPRN(总线优先级请求)和 BPRO(总线优先级输出)信号。
- 当一个设备需要中断 CPU 时,它会通过 BPRN 信号向总线发出请求。
- 请求信号会沿着菊花链传递。如果一个设备没有请求中断,它会将 BPRN 信号传递到下一个设备;如果它自己需要请求中断,则会阻止信号的传递。
- 离总线终端最近的设备拥有最高优先级(图中为 Master 1),最远的设备优先级最低(图中为 Master 3)。
- 拥有最高优先级的设备会获得总线的使用权,然后向 CPU 发出中断请求。
- CPU 收到中断请求后,会通过 BPRO 信号向设备发送确认信号,设备收到确认信号后才能真正发起中断
处理多个中断
禁用中断:CPU 在处理当前中断时暂时禁用所有其他中断。
定义优先级:定义优先级是一种更为复杂和灵活的中断处理方式,允许高优先级中断打断低优先级中断。
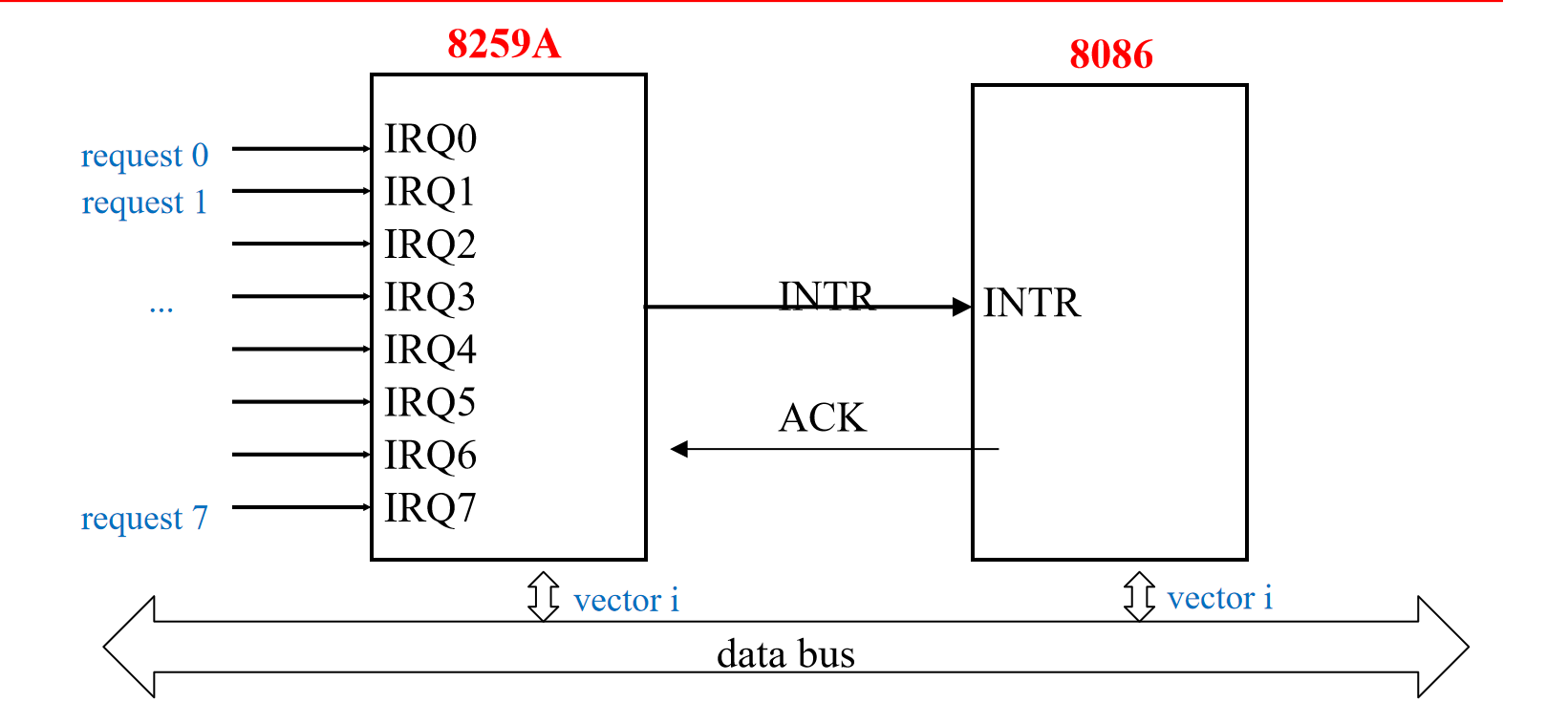
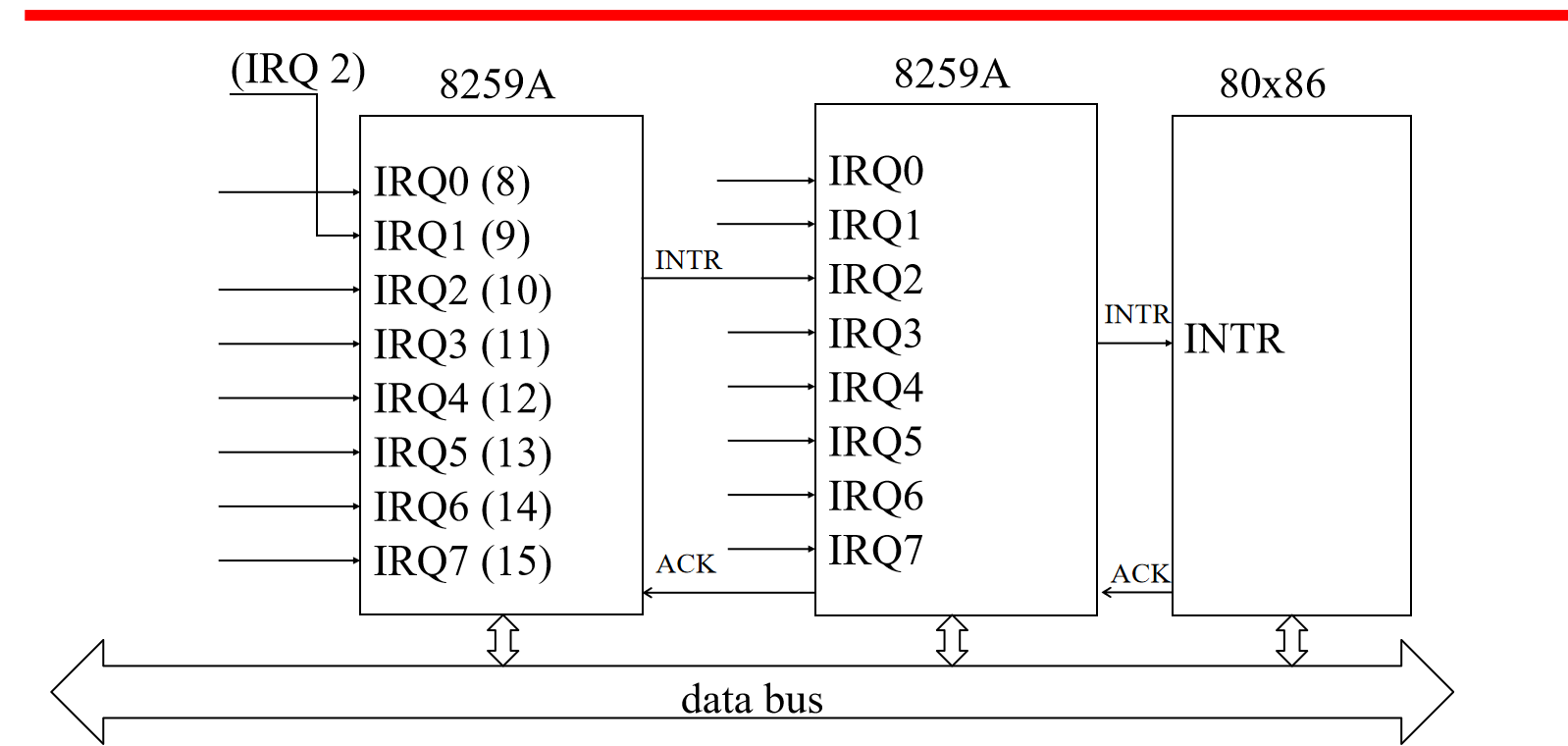
中断执行过程
中断控制器接收外设中断申请
中断控制器定优先级
中断控制器向CPU发中断请求
CPU响应中断
中断控制器发送正确的中断向量
CPU处理中断
4.DMA
CPU 告知 DMA 控制器
- 读/写(操作类型)
- 设备地址(要访问的设备)
- 内存块起始地址(用于数据传输)
- 要传输的数据量
周期挪用
- DMA控制器接管总线一个周期,DMA控制器会完成一个字数据的传输,即将数据从设备传输到内存,或者从内存传输到设备。
- 周期挪用不同于中断。中断会打断CPU的当前任务,并保存现场,而周期挪用只是短暂地“借用”总线,CPU并不会切换上下文,也不需要保存和恢复现场。
- 周期挪用发生在CPU即将访问总线进行数据读取或写入操作之前。
- 虽然周期挪用会占用CPU周期,从而降低CPU的速度,但由于DMA控制器可以直接控制数据传输,因此比CPU自己执行传输要快得多。
三种结构
- 单总线,独立 DMA 控制器

数据传输需要两次占用总线,CPU 可能被暂停两次 [I/O2DMA,DMA2Memory]
- 单总线,集成 DMA 控制器
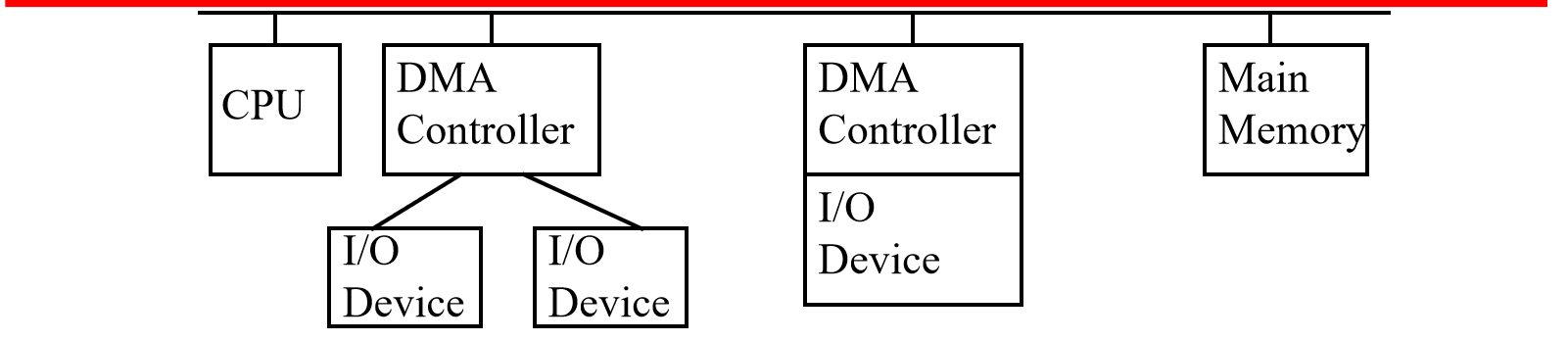
集成的 DMA 控制器可以支持连接到它的多个 I/O 设备。
数据传输只需一次占用总线,CPU 只会被暂停一次
- 独立 I/O 总线
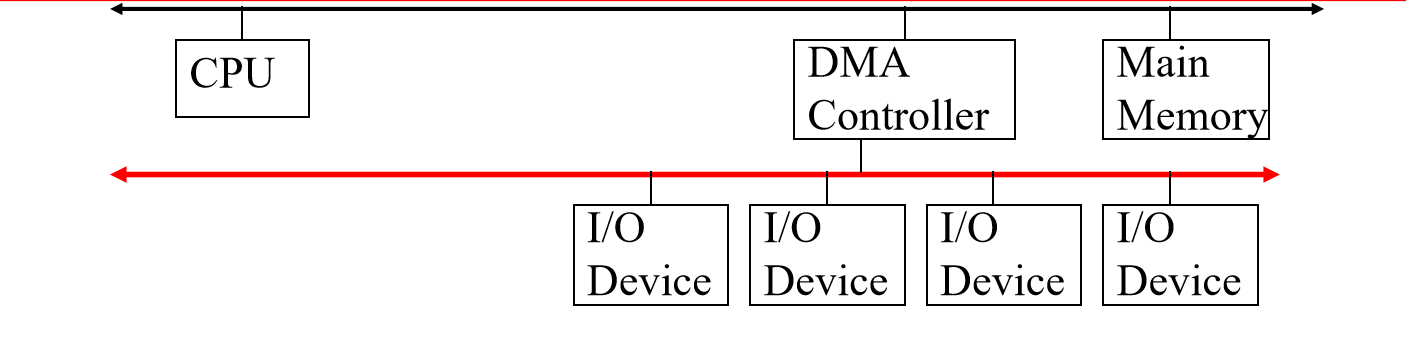
所有支持 DMA 的 I/O 设备都可以连接到独立的 I/O 总线上。
数据传输只需一次占用总线,CPU 只会被暂停一次
四.操作系统支持
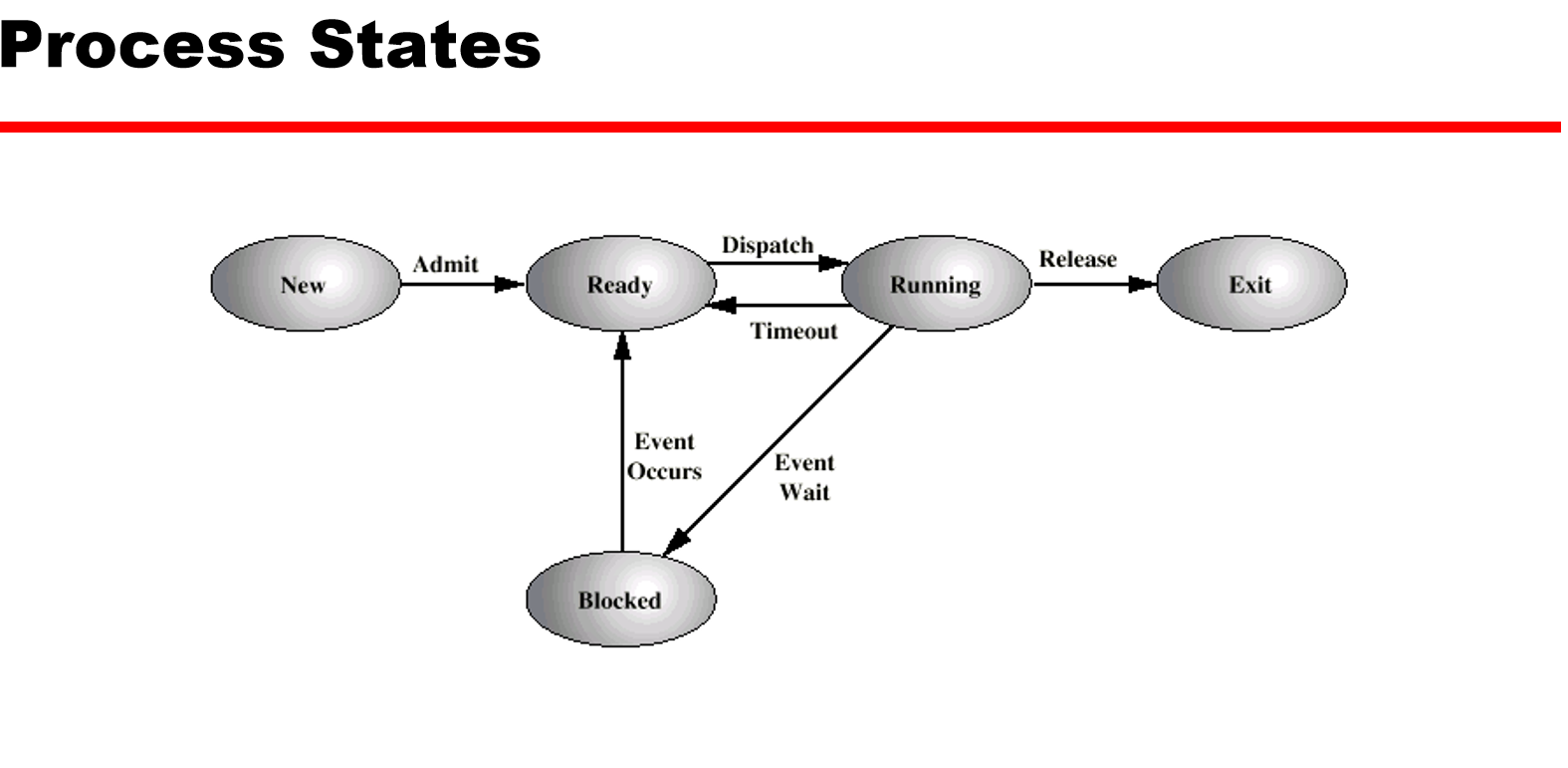
1.调度器
长期调度决定了哪些程序可以被提交到系统中进行处理。它主要负责以下工作:
从等待队列中选择合适的程序,将其加载到内存中,准备执行。
通过控制内存中程序的数量,来决定系统运行的并发程度。
一旦程序被提交,它就变成了短期调度器所管理的进程。
有时,长期调度器也会将一些进程交换到外存中,以便腾出空间给其他进程使用。这些被交换出去的进程由中期调度器管理。
短期调度也称为CPU调度,它负责决定将CPU时间分配给哪个进程,以及何时进行进程切换。
- 短期调度器决定哪个进程可以在下一个时间片中使用CPU,因此它的决策粒度非常细。时间片是CPU分配给每个进程的时间单位。
2.状态图
五.计算机算数
1.表示与加减
符号-大小:
最左边一位只代表符号位,0代表正数,1代表负数
2的补码:
负数的话要 取绝对值的二进制形式,按位取反,将取反后的二进制数加1
逻辑其实很简单+1+(-1)=0,即0001+1111 = 10000 [四位数运算,溢出的最高位的1忽略]
值得注意的是,以4位为例,最大数是+7,最小数是-8,1000代表-8而非+8
同时也可以发现最左边一位在表示大小的同时也能表示符号,0+ 1-
如果要把4位拓展到8位,要用最高位将空位补齐
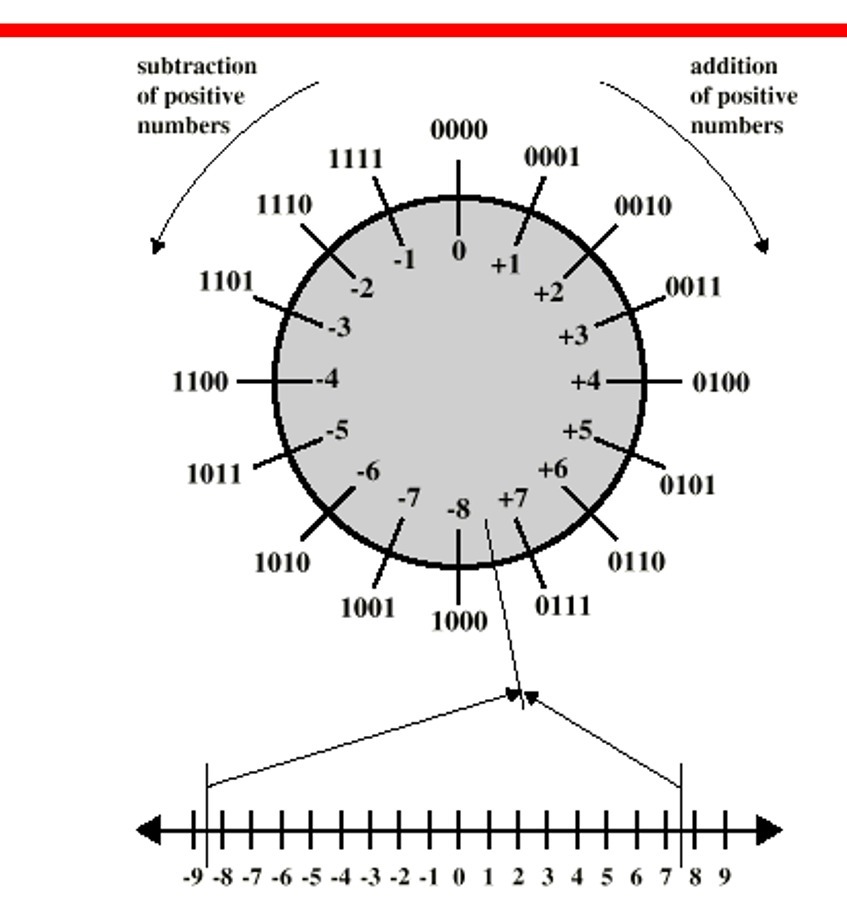
加法很简单,竖式相加,逢二进一,最高位溢出省略
减法无非就是 减去一个数等于加上它的负数
2.整数乘除法
普通乘法运算
看上去和十字进制没啥区别
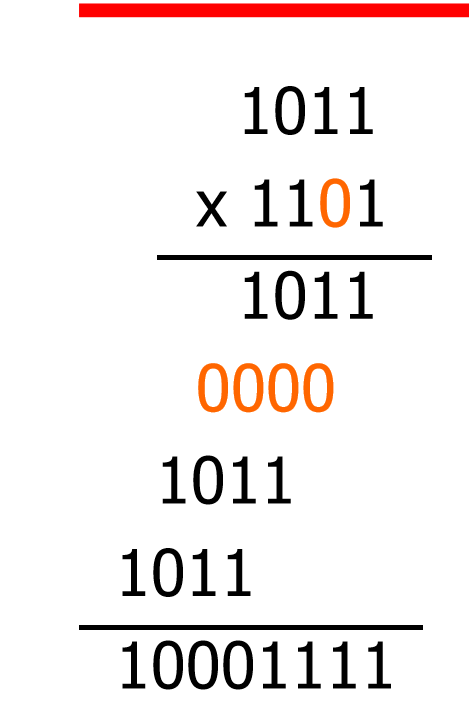
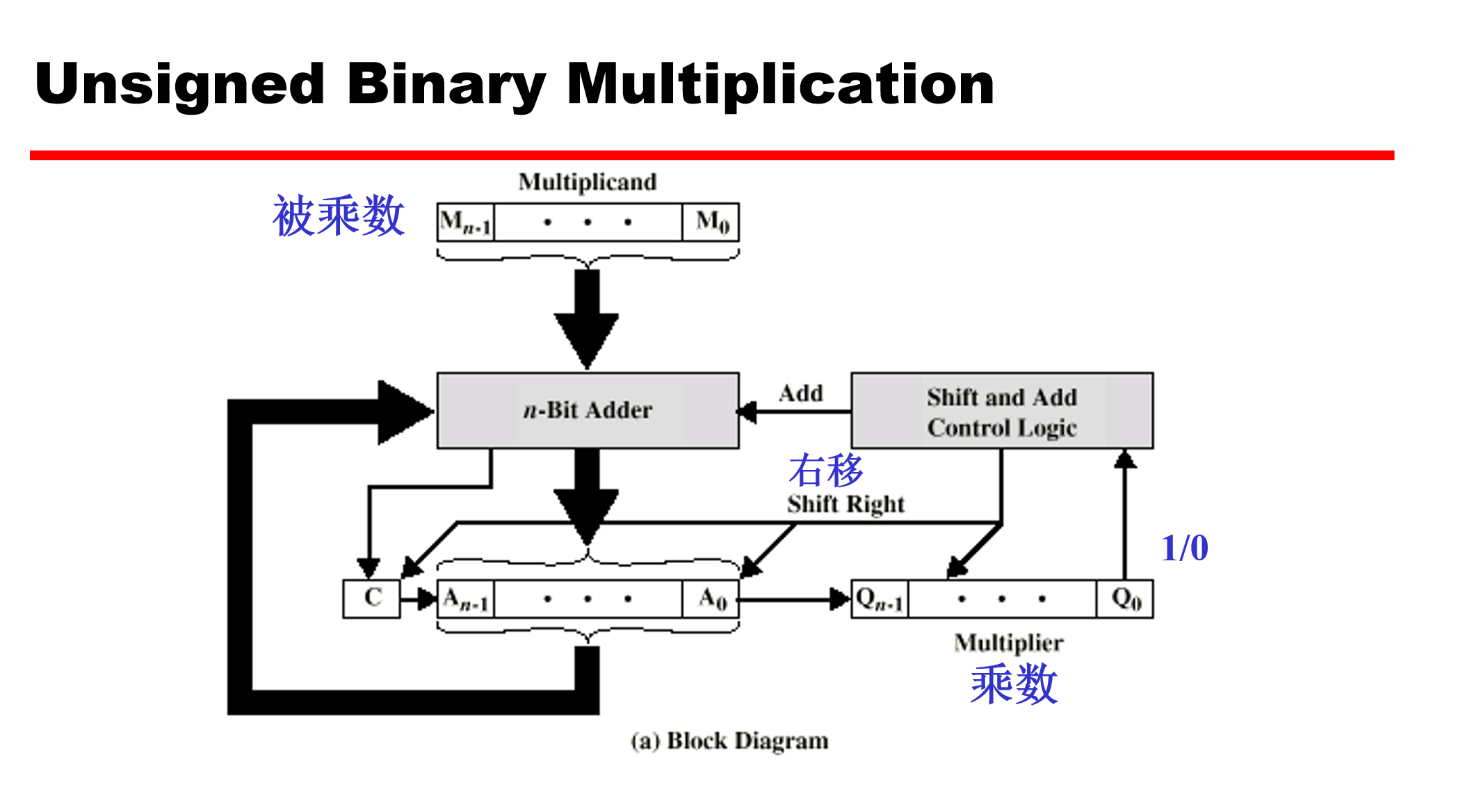
实现原理
- 首先,将被乘数加载到 n 位加法器的输入端,将乘数加载到 Q 寄存器中。
- 然后,根据乘数的最低位 (Q0) 来决定是否将被乘数加到 A 寄存器中。如果 Q0 为 1,则将被乘数加到 A 寄存器中;如果 Q0 为 0,则不进行加法操作 [乘1得本身,乘0则是加上0忽略]。
- 接着,将 A 寄存器和 Q 寄存器的内容一起右移一位 [相当于把下一次的要加的值在竖式运算中左移],注意A寄存器的最后一位移入Q的最高位。
- 重复步骤 2 和 3,直到处理完原来乘数的所有位 [即n位]。
- 最终 A 寄存器和 Q 寄存器会共同存储完整的乘积结果。
上面的演示仅用于整数,若是负数运算
如果任何一个数字是负数,取绝对值,然后向上面一样执行乘法运算
如果原始数字是正负相乘,则对乘法结果取其负数形式。
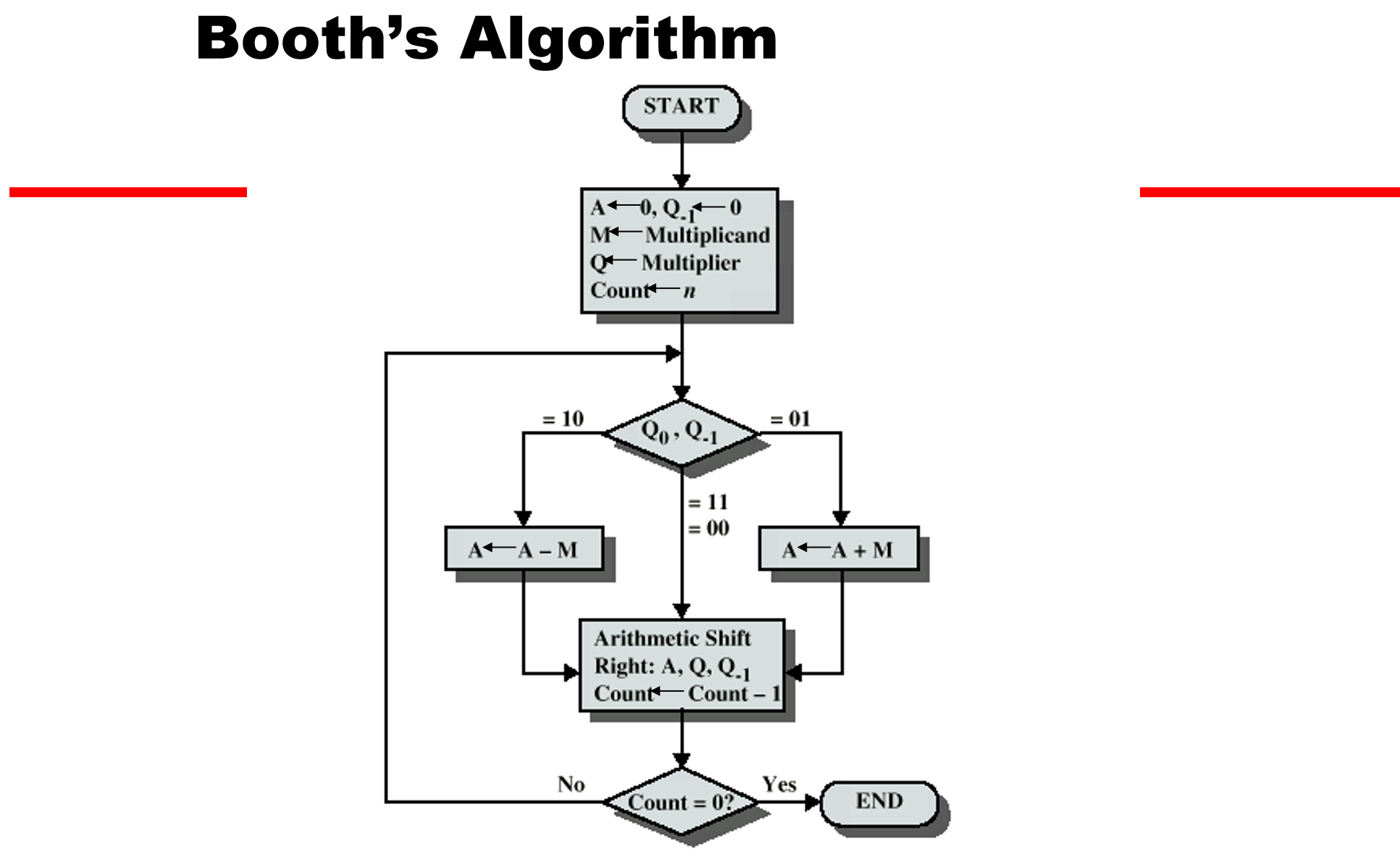
布斯算法
和普通的乘法运算相比,用到了Q寄存器右移后的一位Q-1
当Q0与Q-1的编码分别是是10时,寄存器A减去被乘数,是01时加上被乘数
如果是00或者11则不作处理
然后A寄存器与Q寄存器右移
剩下的操作其实与普通乘法无异
- 原理:
面对二进制数1111这一串连续的1时,我们完全可以把它看作10000-1,
同样的,面对一个被乘数m乘上1111时,我们也可以看作被乘数m*(10000-1)
在下面的布斯算法流程图中我们可以发现当遇到10时说明是连续1的开始,也就是最低位,此时是要被减去的 [如上例中的1]
而遇到01时说明是连续1的结尾,此时是要加上的 [如上例中的10000]
而遇到00或11则无需其他操作
这就是布斯算法的基本原理
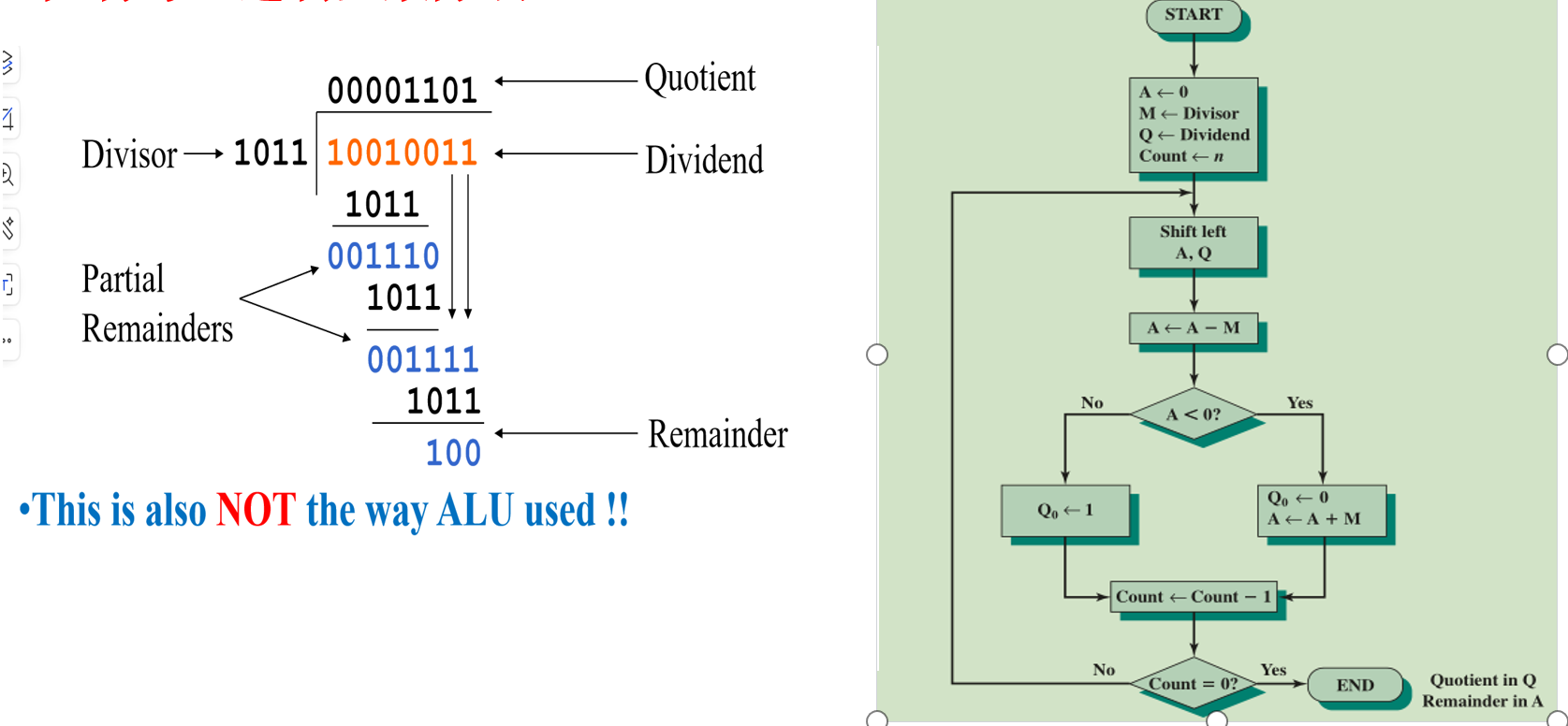
整数的除法
寄存器A用来存余数,而寄存器Q用来存商 [初始值是被除数] ,寄存器M存放除数
将寄存器 A 和 Q 的内容左移一位,相当于将部分余数左移一位并将商的下一位移入 Q 的最低位 [Q的最高位会移入A的最低位]。
将寄存器 A 的内容减去除数 M,相当于用当前的部分余数与除数进行比较。
当前的部分余数小于除数。说明当前位无法进行除法,需要恢复余数,将 Q 的最低位置为 0,并将 A 的内容加上 M 恢复之前的部分余数。
否则说明当前位可以进行除法,将 Q 的最低位置为 1。
继续左移A与Q,并反复执行操作,除尽被除数的位数即可退出
3.浮点表示法
二进制数如何表示小数
- 固定? 一种方法是固定小数点的位置,但这会限制可以表示的数的范围和精度。
- 移动?另一种方法是使用“浮动”的小数点,也就是用一部分位来表示小数点的位置,这也就是“浮点数”的概念。

上图是32位浮点数的表示法
1个符号位,8位指数以及23位尾数
以数6.25为例
转为2进制是110.01,即1.1001 x 2^2
指数部分是2,需要加上偏移码127,算出129,129转化为二进制即是指数的二进制形式
浮点数有一个规范,就是尾数去掉小数点前的1后必须 满足 .0.5 <= abs(尾数) < 1
1.1001去掉小数点前的1是.1001,确实大于0.5 (.1),并且小于1 (1.)
因此1001之后补0补满23位就是尾数的二进制形式了
如果是整数符号位是0,负数的话符号位直接改成1即可
浮点的范围
- 偏移码127,8位二进制数,所以可以表示的精度范围应该再2^(-127)到2^128之间
指数需要偏移码的理由在于:如果直接使用8位有符号数的表示法,比较大小时还要额外留意符号位,而加上偏移码127后符号一致,可以直接比较大小,即无符号比较更高效
- 在精度正负2^(-127)边界以下,单精度浮点数将无法表示,此时发生了向下溢出
在精度2^128时找一个向上溢出的界限,此时就要看尾数的范围了,容易得出尾数最大可用1+ 2^(-23)表示 [或者说是2 - 2^(-23) ]
所以当 正负 (2 - 2^(-23)) x 2^128 时,发生了向上溢出
- 双精度浮点数共有64位,指数部分有11位
浮点的运算
- 加减
找零点—>对阶—>尾数加减—>规格化
- 乘除
找零点—>指数直接加减—>尾数执行乘除法—>符号位单独处理—>规格化—>舍入
注意:所有中间结果都应该使用双倍精度存储,以减少精度损失
- 关于舍入
向上(下)舍入,可以类比向上(下)取整 [正负情况下是不同的]
向0舍入,直接去除精度外的部分
向近舍入,舍入为最近的偶数
六.其他知识
1.指令集与寻址模式
什么是指令集
CPU 可理解的完整指令集合
指令集的元素
- 操作码
- 源操作数引用/访问
- 结果操作数引用
- 下一指令引用
指令的类型
- 数据处理
- 数据存储
- 数据移动
- 程序流程控制
寻址模式
立即寻址
直接寻址
间接寻址
寄存器寻址
寄存器间接寻址
2.指令周期
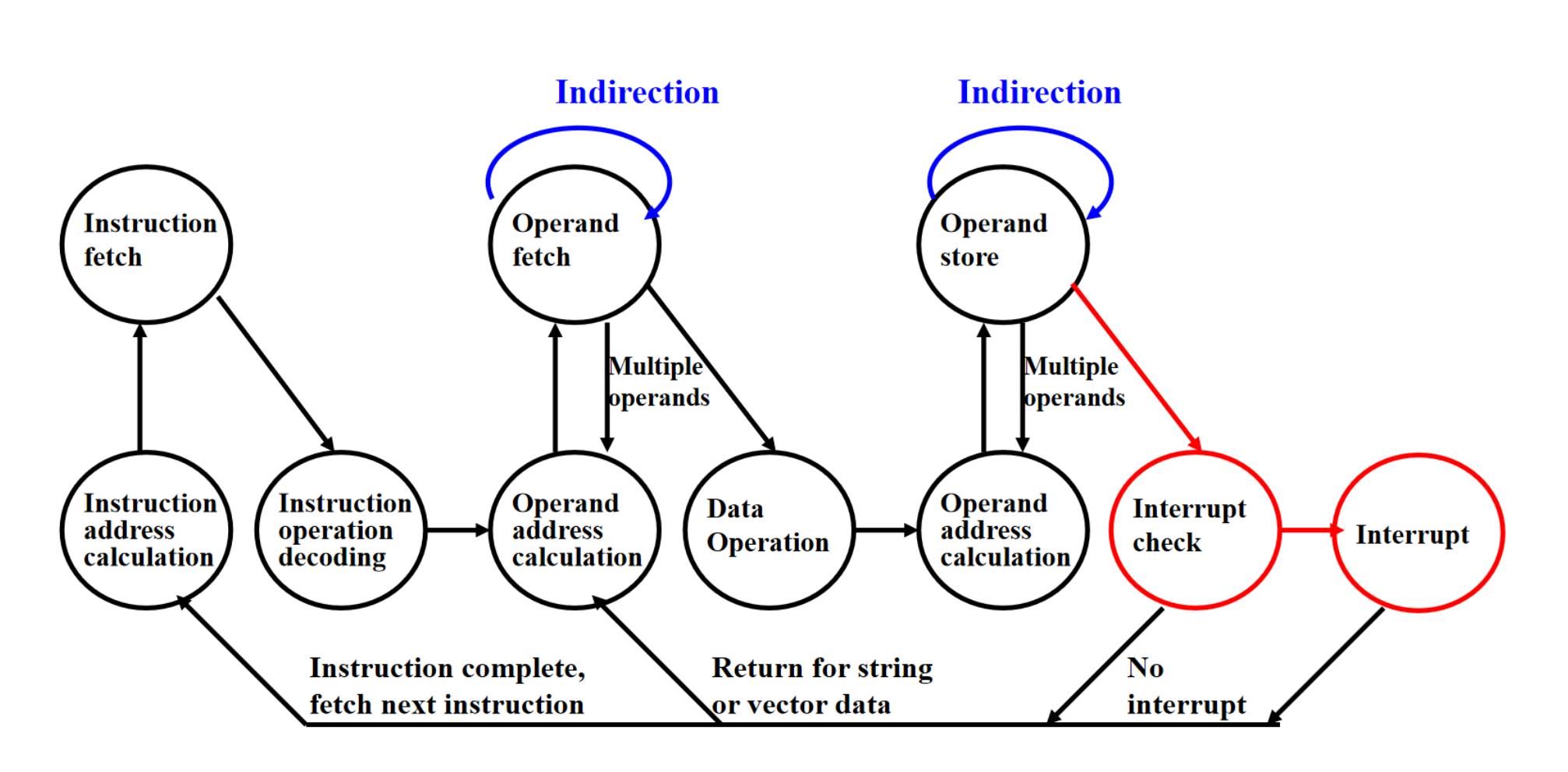
3.RISC精简指令集
RISC 架构的其他特征:
- 1每个周期执行一条指令
- 2寄存器到寄存器的操作
- 3少量简单的寻址模式
- 4少量简单的指令格式
- 5硬连线设计(无微代码)
- 6固定指令格式
- 7需要更多编译时间/精力
总而言之,RISC 处理器通过简化指令和优化流水线,实现了更高的执行效率。
从指令上:1 4 6
从硬件上:2 3 5
从开发者上:7
- Title: 计算机组成原理小记
- Author: TangSong404
- Created at : 2024-06-26 00:00:00
- Updated at : 2025-03-31 00:01:47
- Link: https://www.tangsong404.top/2024/06/26/underlying/computer_composition/
- License: This work is licensed under CC BY-NC-SA 4.0.