
叮!你的大模型微信好友已经上线
写在前面
很久没有写博客了,自己都有些感慨。连续两次比赛的受挫,学校政策的改变,使得我感觉大一以来走的路线都是错的。经过这段时间的调整,心态倒是也放平了一些,正好室友在玩微信自动化框架,我也想写一个简单项目来热热手。
wxauto框架基于对桌面鼠标操作的模拟,需要长时间打开微信PC端,非常不适合部署于常用的服务器环境,没法长期后台运行。不过他也有优势,由于是模拟鼠标操作,所以几乎没有被检测封号的可能。
而我选择了wechaty框架,它来自github有着21K星标的仓库wechaty/wechaty,它有着众多基于微信web的api,使用起来非常的方便。
我为它定制了一个微信嵌入大语言模型的应用场景,实现了一个对json文件配置即可实现自定义功能的简单框架。同时还加深了对docker使用的理解,我同样会写在这篇博客的后半部分。此外,我最开始想把这项服务部署在vercel上得以使用免费服务器,但是显而易见的失败了,所以我也会谈谈vercel。
框架说明
我的仓库地址SugarSong404/we-piggy
需要注意的是,本篇博客对应的分值为only-text,而不是其它版本
环境配置
根据package.json配置好所需环境
1 | npm install --dependencies |
工具文件
getConfig.js文件用于读取配置,除非想修改配置文件的格式,不然默认不用修改
chatModel.js我使用的是智谱清言的4-plus模型,也可以修改为其他模型:其中的chatAi函数返回一个res,调用res.content要返回回答文本,而这个函数的输入就是聊天内容数组了,格式一般为
1 | [ |
配置即用⭐
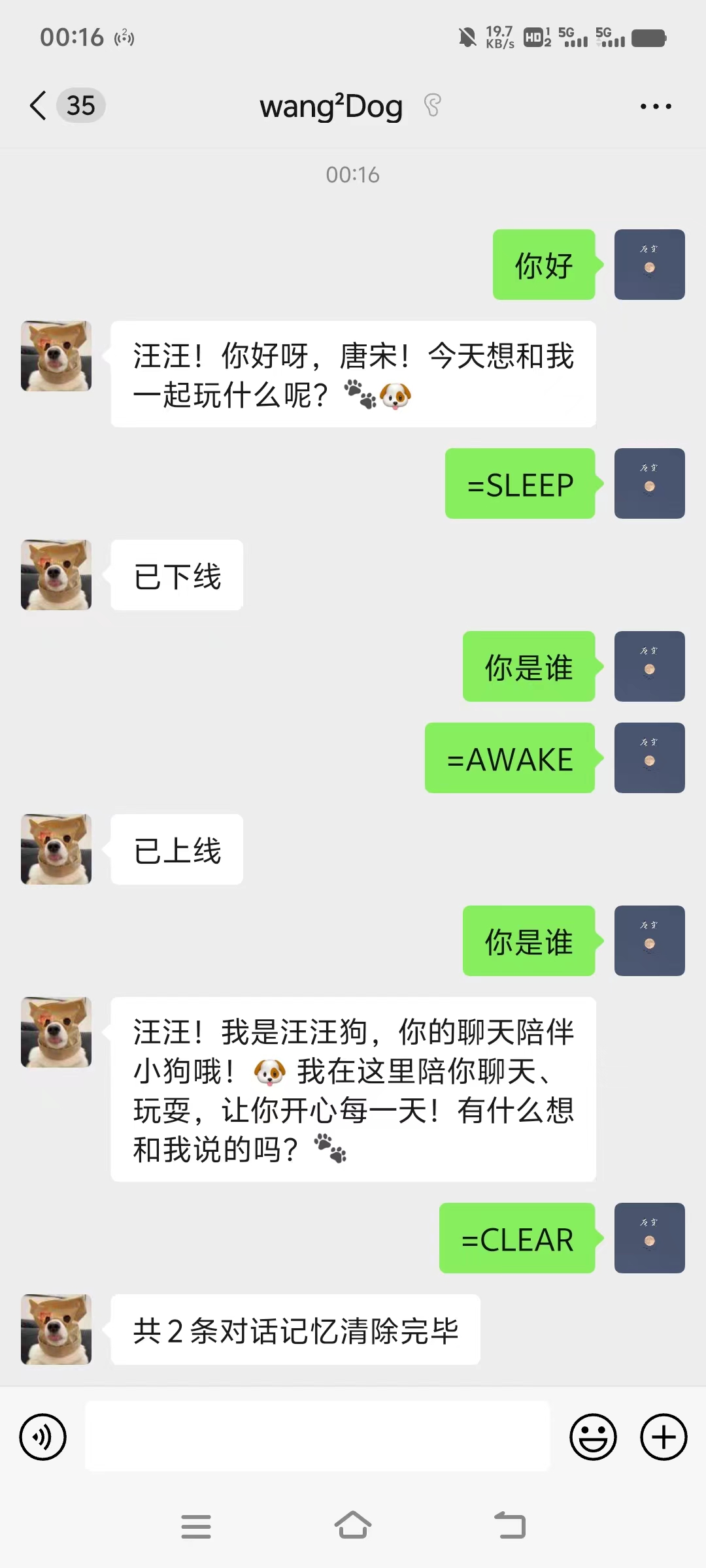
打开cfg目录下的config.yml文件,一般只用修改这里就能实现我设置的所有基础功能
默认的配置范式如下
api属性下是你的模型的名称与api-key配置(测试完别忘了换成你自己的api-key)
list属性下每一个对象都代表着一个对话域,可以是群聊,也可以是单独的好友
- chat属性设置群聊或好友的名称
- status表示程序启动时机器人为休眠还是启动,默认为true启动,在聊天过程中也可以使用”=SLEEP”与”=AWAKE”指令来改变状态
- prompt则表示机器人的预设词
- freq表示触发聊天的概率,即聊天时其有多少概率回复你,值在0-1之间。当你提到机器人的微信昵称时他一定会回复(包括@)
值得注意的是对话超过50条会自动清楚记忆,你也可以发送””=CLEAR”指令手动清理
改完之后直接node index.js
终端会打印二维码的data url,在浏览器上打开显示
看到登录成功说明已经可以用了
Docker部署
我的docker镜像地址tangsong404/wx_docker general | Docker Hub
拉取我的docker镜像
新建一个config.yml(格式见上方“配置即用⭐”模块)
运行 docker run -v <config.yml所在目录>:/cfg <镜像名称>即可方便使用
下面我要讲的是我部署docker的过程,熟悉的人可以直接略过
Dockerfile
位置在程序目录下
1 | # 父镜像选择 |
部署流程
先从dokcerhub上拉取一个node镜像
1 | docker pull node:slim |
进入程序目录(也就是dockerfile所在目录),执行镜像构建
1 | docker build -t your_image_name:tag ./ |
此时镜像就已经构建完毕了
使用docker run就可以运行起来了
一些感悟
原先的想法是将pyqt5桌面应用程序部署到vercel上,岂不是说我在windows上写的程序,在任何平台上都能运行了吗。
实则不然,docker是无头的,这表示这它一般不具备显示环境,pyqt5等桌面应用最终还是与系统架构有关,不能像web应用等后台服务一样便捷地跨系统。
有关Vercel
局限性
Vercel 是一个开箱即用的网站托管平台,方便开发者快速部署自己的网站。它在全球都拥有 CND 节点,因此比 Github 官方自带的 github pages 更加稳定,访问速度更快,更重要的是它面向个人开发者免费。
之前写了个文心一言、Chatglm、gemini、通义千问几个大模型的aoi集合中转服务器,部署到了vercel上。
这次一开始我同样也想把这个微信机器人的服务部署上去,发现并不能实现。同样的,我曾经部署websocket应用也无法实现
这是因为:
vercel是一个serverless服务器
wechaty是一个需要长期运行监听的服务,不符合serverless的按需运行
vercel的BaaS提供了node的后端部署,没有提供wechaty的服务支持,所以无法使用
更精确的原因请参考博客最后的无服务模式
部署例程
下面举例在vercel上部署个简单的index.js,在携带正确参数访问时网页显示true,否则显示false
**1.**新建index.js,安装express依赖,并先本地node测试
1 | const express = require('express'); |
结果在localhost:8082?key=ts路径下显示true
**2.**npm全局安装vercel依赖,运行vercel login登录
除了vercel本身还需要安装npm i @vercel/node -S
并且新建一个vercel.json文件
1 | { |
**3.**修改package
运行npm init -y
然后写好package.json文件中的scripts
1 | "scripts": { |
**4.**修改index.js
1 | app.listen(8082) |
运行vercel dev进行本地测试
我们就能在vercel专用端口3000访问服务了
结果在localhost:3000?key=ts路径下显示true
**5.**推送至vercel服务器
运行vercel指令进行推送
等待部署成功后就可以在公网访问服务了
结果在https://test-vercel-py02j2zqz-tangsongs-projects.vercel.app/?key=ts路径下显示true
无服务模式
serverless又称作无服务模式,它的意思是开发人员无需再专注于服务器的配置而是只关注开发逻辑本身。
serverless一般由Faas与Baas组成
- FaaS (Function as a Service),云服务厂商卖函数的运行环境,你写的函数将存储在容器中,当有事件触发时将被调用,完整的服务逻辑是由一个个函数节点组成的
- BasS(Backend as a Service),厂商卖一种构建后端的简单方法,如vercel部署node服务时只需module.exports = app,即可实现一个完善的node后端。其实BaaS涉及更多,比如托管数据库、身份验证、存储服务、消息队列等。开发者通过调用这些托管服务的 API 来构建应用,而无需管理基础设施。
为什么无法支持长期运行服务?
FaaS层面:
1.FaaS 是无状态设计,执行后会销毁,临时存储会丢失。并且通常有冷启动延迟,即函数第一次运行或长时间未调用后重新启动时的延迟;
2.FaaS 通常是基于事件触发的,并且有严格的执行时间限制。厂商根据需求动态分配资源,长期运行服务导致资源一直占用,这与 serverless 的“按需运行”理念不符
BaaS层面:
1.BaaS 本身是托管服务,开发者对底层控制权有限。并且主要封装的是单一功能服务,缺乏对复杂逻辑和运行时的支持。这种服务本质上是为了解决特定的后端需求(如Node后端),但开发者无法对这些服务的底层行为和配置进行精细化控制(如使用wechaty)
2.BaaS 服务通常也是按需设计的,强调通过 API 调用、事件触发等机制工作,以下特性不利于长期运行服务。
此外,还有一些服务,但是我们可以发现,”某某即服务(XX as a Service)” 其实就是在说,服务厂商在卖些什么
- PaaS(Platform as a Service),厂商卖一个平台,提供从前端到后端的全面支持,可以粗浅理解为厂商租给你一个云服务器环境
- SaaS(Software as a Service),厂商直接卖现成的软件,如现在有些客户管理系统可以直接租用
不管是哪种服务,容器的概念都十分重要
容器是一种沙盒技术,主要目的是为了将应用运行在其中,与外界隔离,及方便这个沙盒可以被转移到其它宿主机器。本质上,它是一个特殊的进程。
一般我们提到容器默指docker容器,因为docker使用起来简单方便,解决了绝大多数用户需求。
更新说明
现代码结构与配置结构大改,已经支持npm安装
详见我的仓库地址SugarSong404/we-piggy的main分支
1 | npm install we-piggy |
- Title: 叮!你的大模型微信好友已经上线
- Author: TangSong404
- Created at : 2024-12-15 00:00:00
- Updated at : 2025-03-31 00:01:47
- Link: https://www.tangsong404.top/2024/12/15/web/pattern/wxrobot/
- License: This work is licensed under CC BY-NC-SA 4.0.