我的学习项目例程与数据集将持续分享至ML_study_repo仓库中
线性回归
概率密度函数推导
最大似然值推导(最小二乘法)
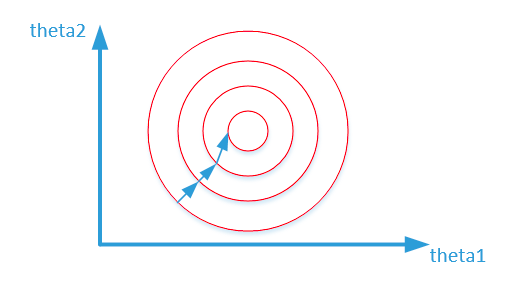
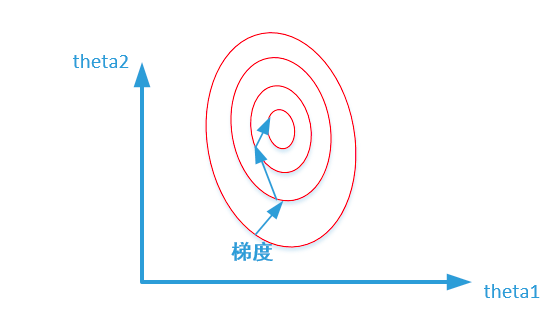
梯度下降法
模型评估方法
非线性回归
标准化

正则化
逻辑回归
逻辑回归概率密度函数推导
最大似然与梯度下降
多分类逻辑回归sigmoid
信息熵与交叉熵
多分类逻辑回归softmax
两种激活函数的比较
| 特性 |
Sigmoid |
Softmax |
| 适用场景 |
多标签分类,一个数据可以分到多类 |
单标签分类,一个数据只能分到一类 |
| 类别独立性 |
每个类别概率独立预测,互不影响 |
类别间有概率竞争关系,概率总和为 1 |
| 输出范围 |
每个类别的概率在 [0, 1] |
概率分布,总和为 1 |
| 典型任务 |
图像多标签分类,文本情感分析 |
图像单标签分类(如手写数字分类) |